Out-of-Sample Testing in Climate Science
This post discusses model-as-truth experiments (to gauge the skill of a calibrated statistical model on unseen data) as used in my 2018 Earth System Dynamics paper. Just as in statistical learning, out-of-sample testing in climate science is essential.
An important part of my PhD is the optimal selection of a subset of climate models from the original pool of models (e.g. the multi-model ensemble part of CMIP5). It is essentially a calibration process with binary weights, where we either include a climate model in the subset or we don’t. Similar to the supervised machine learning framework, the calibration is done in-sample relative to some given truth by minimising a cost function. Once we identify a subset of climate models, we need to test it out-of-sample, based on data we have not used in the calibration process.
Here is a simplified schematic that illustrates this process of calibrating in-sample and testing the subset out-of-sample.
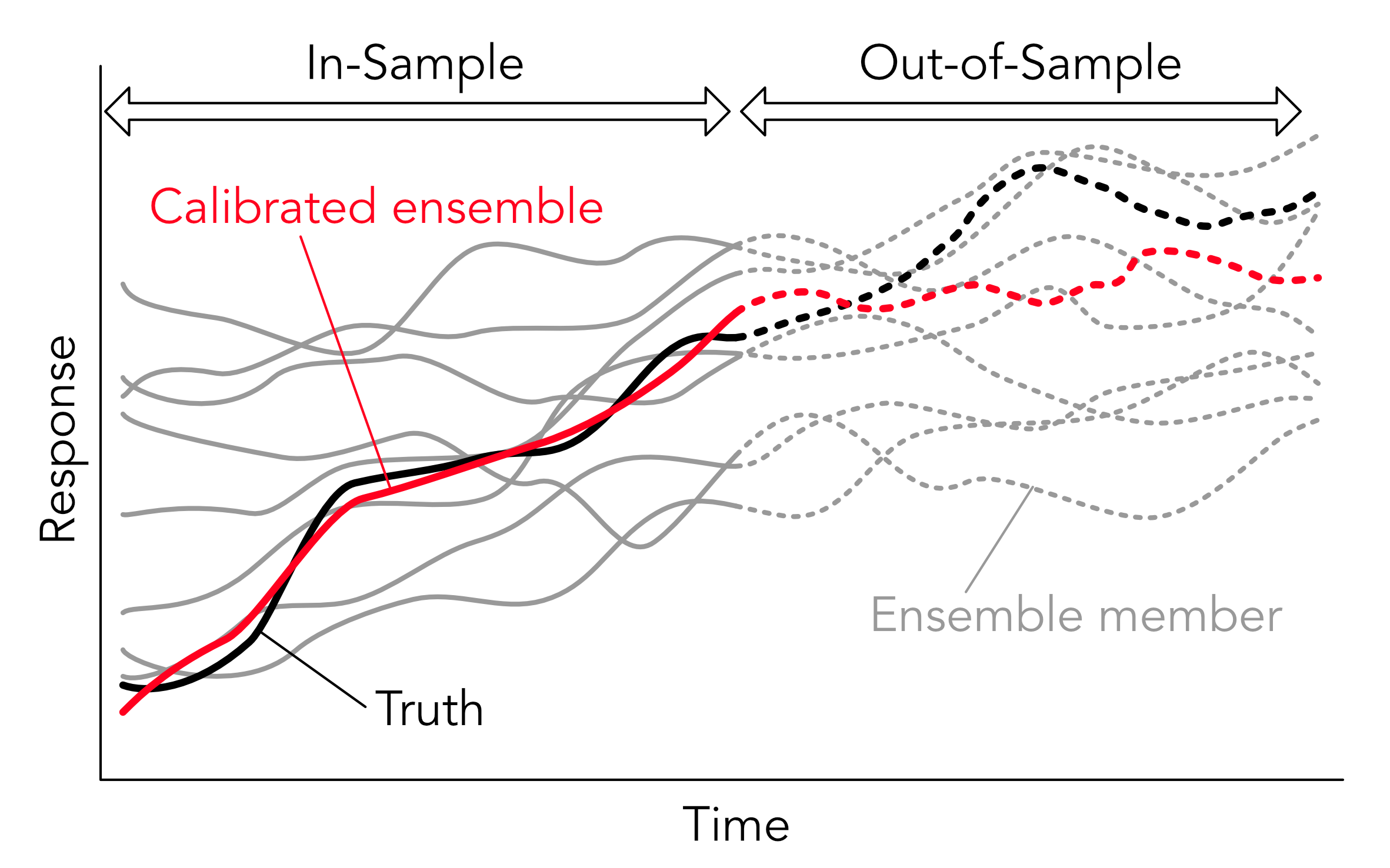
The grey curves are the individual climate models and the black curve is the truth. The calibrated ensemble is shown in red and is minimising a given cost function relative to the truth in-sample. As future climate cannot be observed, we commonly use a given model simulation as our truth. This means that we now have “pseudo-observations” in the out-of-sample period (dotted black curve). The skill of the calibrated ensemble (dotted red curve) can now be assessed out-of-sample. In this particular example, the calibrated ensemble performs well in-sample, but skill quickly deteriorates out-of-sample. This is commonly referred-to as overfitting.
As mentioned above, we use a given climate model simulation as our truth. However, how do we select which model to choose as our truth? In climate science, this question is addressed by running so-called model-as-truth experiments (sometimes referred to as perfect model tests). Instead of only using one model as truth, we rotate through all possible models as truth. Here is a schematic of how model-as-truth experiments are set up:
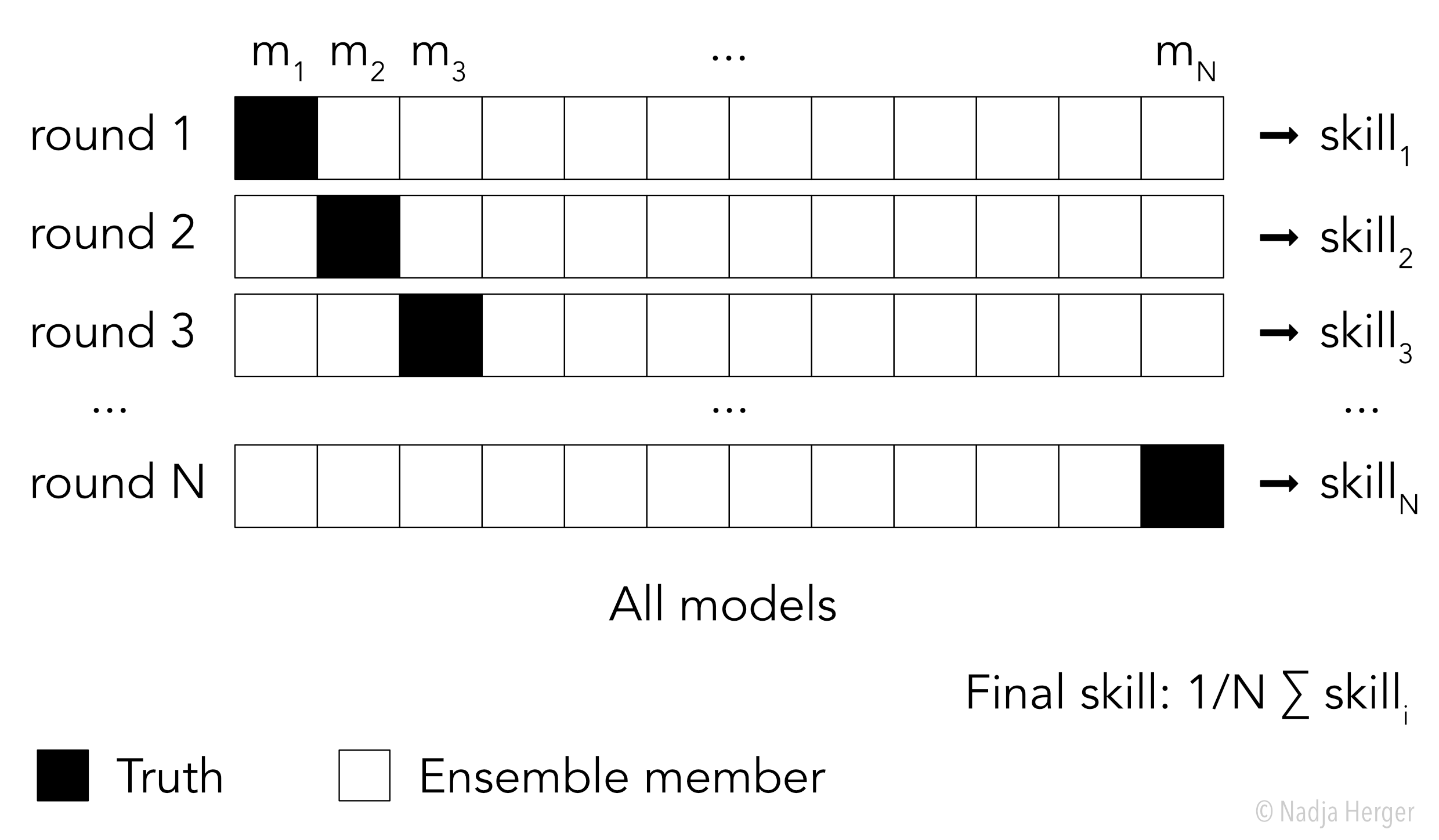
If our ensemble consists of N models, we have N rounds of calibrating an ensemble in-sample and calculating out-of-sample skill. The final skill is then obtained by averaging the skills from the individual rounds. Note, that for a model-as-truth experiment to provide conclusions relevant for the real world, one needs to carefully select the climate models used in those experiments.
If the calibrated subset is found to be skillful out-of-sample, it can subsequently be used to make predictions (or projections, as we call it in climate science). It is important to note that in-sample skill does not guarantee out-of-sample skill.

Welcome to my site! I hope you find something interesting here.
- Lessons learned in AI Governance
- My Journey from Climate Science into Responsible AI
- Photo Clustering
- Multi-objective optimisation and Pareto optimality
- Out-of-Sample Testing in Climate Science
- Climate Change Scarf
- Hackathon
- Combinatorial optimisation with Gurobi
- Visualising the model space with unsupervised learning
- Setting up Jekyll on GitHub Pages